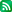(mysql 을 재시작 안해도 max_connections 값이 바로 적용된다.)
또 다른 방법으로
mysql 설정파일(my.ini 또는 my.cnf )을 다음과 같이 설정해주면 된다.
[mysqld]
max_connections = 300
설정파일 변경 후에는 mysql 재시작이 필요하다.max_connections = 300
■ max_connections에 대한 설명
MySQL은 [ 최대 접속수 + 1 ]의 접속을 허용한다. "1"은 관리자 권한 접속을 나타낸다.
문제가 발생했을 경우 관리자가 접속할 수 있게 하기 위해서이다.
시스템에 접속수가 폭주해서 접속이 안되는 경우가 발생한다. (ERROR 1040 (08004): Too many connections)
이런 상황에서 일시적으로 접속수를 증가시킴으로써 에러를 해결하자~.
■ MySQL 접속수 관련 상태를 확인하는 방법
mysql> show variables like '%max_connect%';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| max_connect_errors | 10000 |
| max_connections | 100 |
+--------------------+-------+
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| max_connect_errors | 10000 |
| max_connections | 100 |
+--------------------+-------+
mysql> show status like '%CONNECT%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| Aborted_connects | 200 |
| Connections | 300 |
| Max_used_connections | 101 | ==> 현재 연결된 접속수
| Ssl_client_connects | 0 |
| Ssl_connect_renegotiates | 0 |
| Ssl_finished_connects | 0 |
| Threads_connected | 101 | ==> 연결되었던 최대 접속수
+--------------------------+-------+
7 rows in set (0.00 sec)
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| Aborted_connects | 200 |
| Connections | 300 |
| Max_used_connections | 101 | ==> 현재 연결된 접속수
| Ssl_client_connects | 0 |
| Ssl_connect_renegotiates | 0 |
| Ssl_finished_connects | 0 |
| Threads_connected | 101 | ==> 연결되었던 최대 접속수
+--------------------------+-------+
7 rows in set (0.00 sec)
mysqladmin 실행해서 확인하는 방법
./mysqladmin -u root -p processlist
./mysqladmin -u root -p variables | grep max_connections
./mysqladmin -u root -p variables | grep max_connections